
This section gives an overview of the Server-Side Row Model (SSRM) and provides guidance on when it should be used.
The Server-Side Row Model (SSRM) allows applications to work with very large datasets. This is done by lazy-loading data from the server via the following mechanisms:
- Lazy loading child records from group rows as group rows are expanded.
- Infinite scrolling through data, loading more data as the application scrolls.
Using the SSRM to view a large dataset is demonstrated below:
Before diving into the details of how to use the SSRM, the next section provides an overview and explains when it should be used instead of the default Client-Side Row Model.
Overview
When designing a grid-based application, one of the key considerations is how much data needs to be sent from the server to the client. The answer to this determines which Row Model should be selected for the grid.
Client-Side Row Model
The simplest approach is to send all row data to the browser in response to a single request at initialisation. For this use case the Client-Side Row Model has been designed.
This scenario is illustrated below where 10,000 records are loaded directly into the browser:
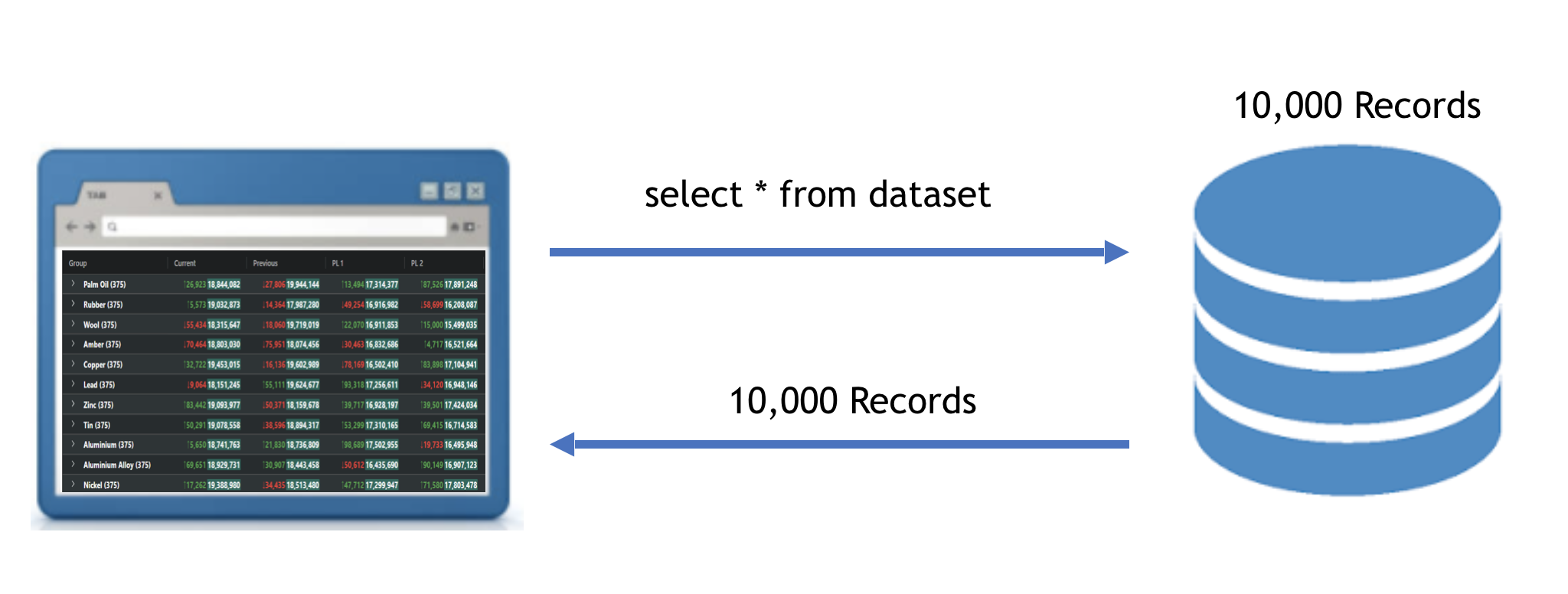
Once the data is loaded into the grid using the Client-Side Row Model, the grid can then do sorting, filtering, grouping etc. on the data inside the grid without requiring further assistance from the application.
The Client-Side Row Model only renders the rows currently visible using DOM Virtualisation, so the upper limit of rows is governed by the browser's memory footprint and data transfer time, rather than any restrictions inside the grid.
Server-Side Row Model
However, many real world applications contain much larger datasets, often involving millions of records. In this case it simply isn't feasible to load all the data into the browser in one go. Instead the data will need to be lazy-loaded as required and then purged to limit the memory footprint in the browser.
This is precisely the problem the SSRM addresses, along with delegating server-side operations such as filtering, sorting, grouping and pivoting.
The following diagram shows the approach used by the SSRM. Here there are 10 million records, however the number of records is only constrained by the limits of the server-side:
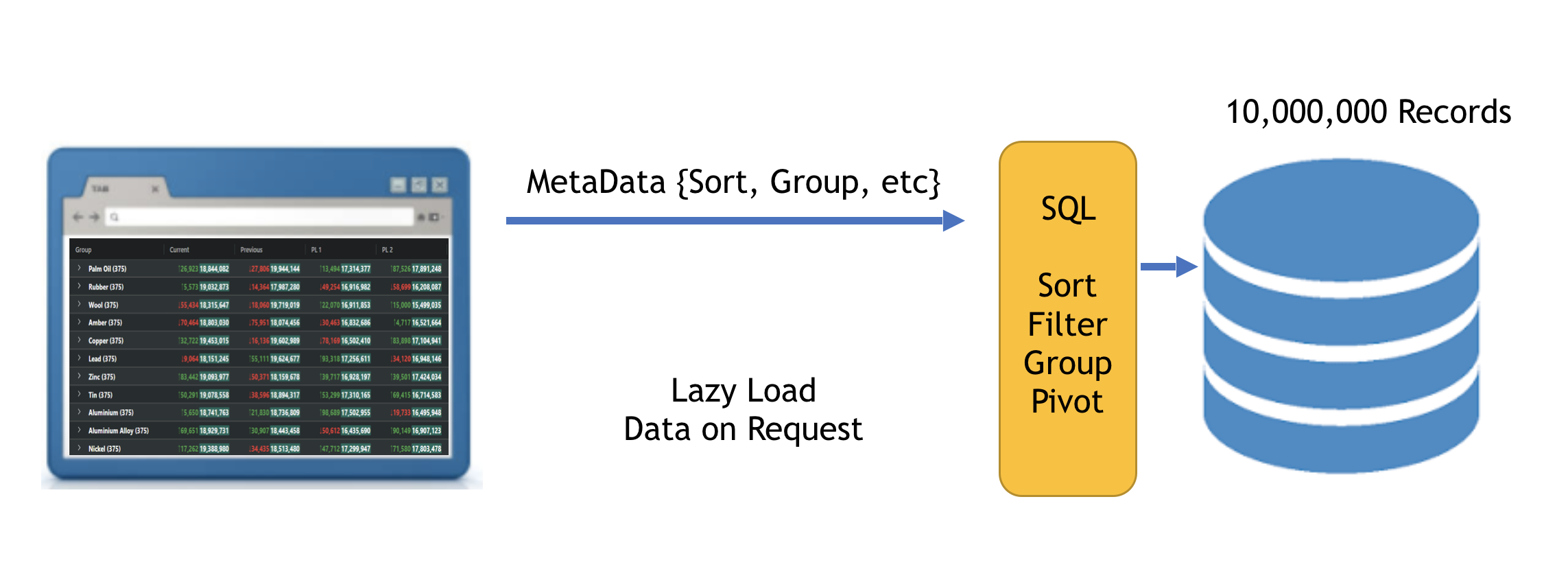
As the user performs operations such as expanding groups, the grid issues requests to the server for more data.
Features
You may benefit from the combination of all these features or just be interested in a subset. The features of the SSRM are:
Lazy-Loading of Groups: The grid will load the top level rows only. Children of groups are only loaded when the user expands the group.
Infinite Scrolling: Rows are read back from the server in blocks to provide the experience of infinite scrolling. This allows viewing very large datasets in the browser by only bringing back data one block of data at a time.
Server-Side Grouping, Pivot and Aggregation: Because the data is coming back from the server one group level at a time, this allows you to do aggregation on the server, returning the aggregated results for the top level parent rows. For example, you could include 'employee count' as an attribute on the returned manager record, to say how many employees a manager manages.
Slice and Dice: Assuming your server-side can build the data query, you can allow the user to use the Grid UI to drag columns around to select what columns you want to group by and aggregate on. What the user selects will then be forwarded to your datasource as part of the request. This feature is advanced and will require some difficult server-side coding from you, however when done your users will have an experience of slicing and dicing large data in real time, something previously only available in expensive reporting tools, which you can now embed into your JavaScript application.
Full Stack Examples
To accompany the examples in the documentation, we also provide the following full stack examples for reference. We advise using the examples in the documentation to learn about the Server-Side Row Model and then using the full stack examples as reference.
The full stack examples are as follows:
- Node.js connecting to MySQL
- Java Server connecting to Oracle
- GraphQL connecting to MySQL
- Java Server connecting to Apache Spark
Next Up
Continue to the next section to learn about the SSRM API Reference.